DeFtunes Data Pipeline
A comprehensive data pipeline for a fictional music streaming service, built with AWS services, Apache Airflow, and modern data engineering practices.
Technology StackTechnologies
Cloud Infrastructure
- AWS S3
Object storage for the data lake
- AWS Glue
Serverless ETL service
- AWS Lambda
Serverless compute for data ingestion
- AWS Redshift
Data warehouse for analytics
Data Processing
- Apache Spark
Distributed data processing
- Apache Iceberg
Table format for data lakes
- AWS Glue Data Quality
Data validation service
- dbt
Data transformation tool
Orchestration
- Apache Airflow
Workflow orchestration platform
- AWS Step Functions
Serverless workflow service
- AWS Glue Workflow
Managed ETL workflows
Infrastructure as Code
- Terraform
Infrastructure provisioning
- AWS CloudFormation
AWS resource templating
- Docker
Container platform for services
Languages & Frameworks
- Python
Primary programming language
- SQL
Data query language
- PySpark
Python API for Apache Spark
Version Control & CI/CD
- Git
Version control system
- GitHub Actions
CI/CD automation
Monitoring & Visualization
- Apache Superset
Data visualization platform
- AWS CloudWatch
Monitoring and observability
- Grafana
Metrics visualization
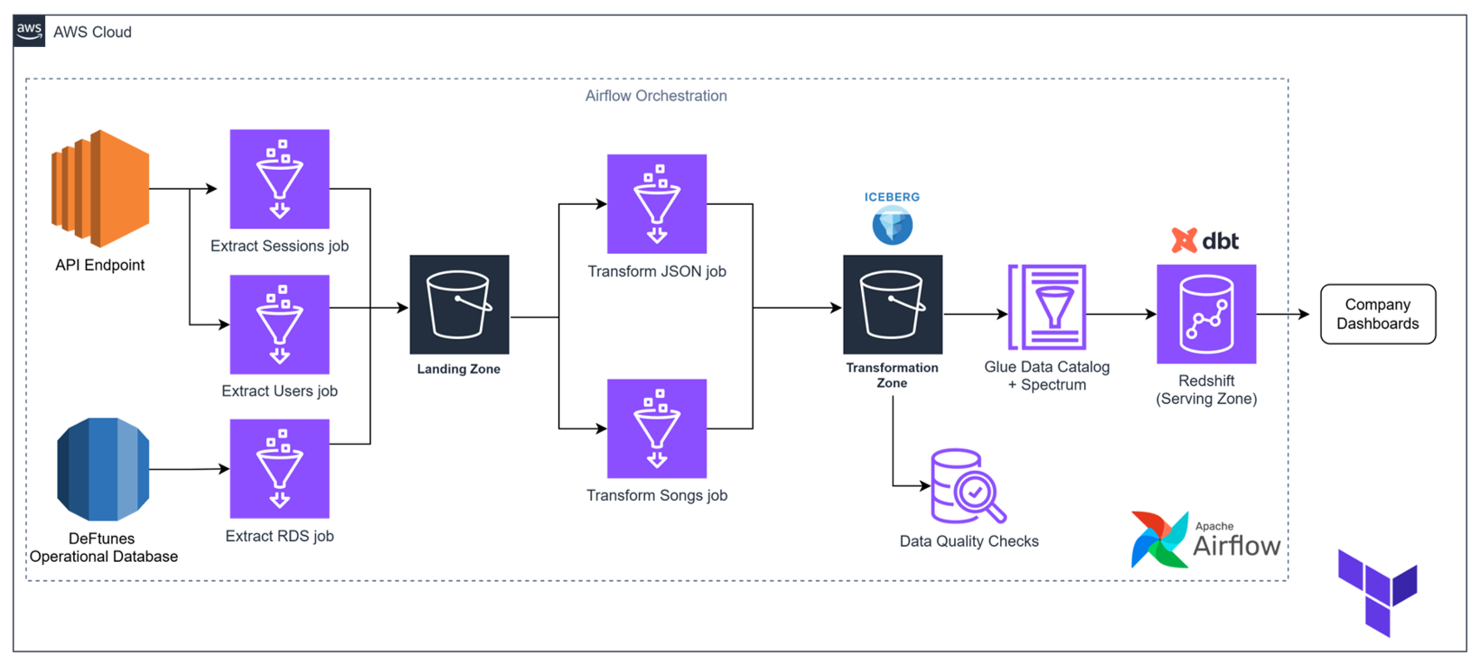
Pipeline Architecture
Data Architecture
The DeFtunes pipeline implements a modern lakehouse pattern with multiple layers for data processing and analytics.
Key Components
Extract Layer
AWS Glue jobs extract data from API endpoints and RDS databases, storing raw data in S3 landing zone with date-based partitioning.
Transform Layer
Glue ETL jobs transform data, adding metadata and proper formatting, storing the result in Apache Iceberg tables.
Data Quality
AWS Glue Data Quality validates data against rule sets that check for completeness, uniqueness, and data type compliance.
Serving Layer
Amazon Redshift hosts the dimensional model (star schema) created with dbt, serving as a data warehouse for analytics.
ETL Code Examples
Data Extraction Process
The extraction process pulls data from API endpoints and databases using AWS Glue jobs.
1import requests
2import json
3import boto3
4import os
5from datetime import datetime
6import logging
7
8# Configure logging
9logging.basicConfig(level=logging.INFO)
10logger = logging.getLogger(__name__)
11
12def get_api_data(endpoint, api_key, params=None):
13 """
14 Fetch data from API endpoint with authentication
15 """
16 headers = {
17 'Authorization': f'Bearer {api_key}',
18 'Content-Type': 'application/json'
19 }
20
21 try:
22 response = requests.get(endpoint, headers=headers, params=params)
23 response.raise_for_status()
24 return response.json()
25 except requests.exceptions.HTTPError as e:
26 logger.error(f"HTTP Error: {e}")
27 raise
28 except requests.exceptions.ConnectionError as e:
29 logger.error(f"Connection Error: {e}")
30 raise
31 except requests.exceptions.Timeout as e:
32 logger.error(f"Timeout Error: {e}")
33 raise
34 except requests.exceptions.RequestException as e:
35 logger.error(f"Request Exception: {e}")
36 raise
37
38def upload_to_s3(data, bucket, key):
39 """
40 Upload data to S3 bucket
41 """
42 s3_client = boto3.client('s3')
43 try:
44 s3_client.put_object(
45 Body=json.dumps(data),
46 Bucket=bucket,
47 Key=key
48 )
49 logger.info(f"Successfully uploaded data to s3://{bucket}/{key}")
50 except Exception as e:
51 logger.error(f"Error uploading to S3: {e}")
52 raise
53
54def lambda_handler(event, context):
55 """
56 AWS Lambda handler for API data extraction
57 """
58 # Get environment variables
59 api_endpoint = os.environ['API_ENDPOINT']
60 api_key = os.environ['API_KEY']
61 s3_bucket = os.environ['S3_BUCKET']
62
63 # Extract date parameters
64 year = event.get('year', datetime.now().strftime('%Y'))
65 month = event.get('month', datetime.now().strftime('%m'))
66
67 # Get API data
68 logger.info(f"Fetching data from {api_endpoint}")
69 api_data = get_api_data(api_endpoint, api_key)
70
71 # Upload to S3
72 s3_key = f"raw/api_data/year={year}/month={month}/data_{datetime.now().strftime('%Y%m%d%H%M%S')}.json"
73 upload_to_s3(api_data, s3_bucket, s3_key)
74
75 return {
76 'statusCode': 200,
77 'body': json.dumps(f"Data extraction completed successfully. Written to s3://{s3_bucket}/{s3_key}")
78 }1import sys
2import datetime
3from awsglue.transforms import *
4from awsglue.utils import getResolvedOptions
5from pyspark.context import SparkContext
6from awsglue.context import GlueContext
7from awsglue.job import Job
8from awsglue.dynamicframe import DynamicFrame
9from pyspark.sql import functions as F
10
11# Get job parameters
12args = getResolvedOptions(sys.argv, [
13 'JOB_NAME',
14 'database_name',
15 'table_name',
16 'connection_name',
17 's3_target_path',
18 'year',
19 'month'
20])
21
22# Initialize Spark context
23sc = SparkContext()
24glueContext = GlueContext(sc)
25spark = glueContext.spark_session
26job = Job(glueContext)
27job.init(args['JOB_NAME'], args)
28
29# Define the JDBC connection
30connection_options = {
31 "url": f"jdbc:mysql://deftunes-db.cluster-xyz.us-west-2.rds.amazonaws.com:3306/{args['database_name']}",
32 "dbtable": args['table_name'],
33 "user": "glue_user",
34 "password": "{{resolve:secretsmanager:deftunes/db-credentials:SecretString:password}}",
35 "classification": "mysql"
36}
37
38# Extract data from source database
39print(f"Extracting data from {args['database_name']}.{args['table_name']}")
40df = glueContext.create_dynamic_frame.from_options(
41 connection_type="mysql",
42 connection_options=connection_options
43).toDF()
44
45# Add extraction metadata
46df = df.withColumn("extract_date", F.lit(datetime.datetime.now()))
47df = df.withColumn("source_table", F.lit(f"{args['database_name']}.{args['table_name']}"))
48
49# Write to S3
50output_path = f"{args['s3_target_path']}/year={args['year']}/month={args['month']}"
51print(f"Writing data to {output_path}")
52
53glueContext.write_dynamic_frame.from_options(
54 frame=DynamicFrame.fromDF(df, glueContext, "df"),
55 connection_type="s3",
56 connection_options={"path": output_path},
57 format="parquet"
58)
59
60# Commit the job
61job.commit()Infrastructure Code
Infrastructure as Code with Terraform
Terraform is used to provision and manage the AWS infrastructure components.
1provider "aws" {
2 region = var.aws_region
3}
4
5module "vpc" {
6 source = "terraform-aws-modules/vpc/aws"
7 version = "~> 4.0"
8
9 name = "deftunes-vpc"
10 cidr = "10.0.0.0/16"
11
12 azs = ["us-west-2a", "us-west-2b", "us-west-2c"]
13 private_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"]
14 public_subnets = ["10.0.101.0/24", "10.0.102.0/24", "10.0.103.0/24"]
15
16 enable_nat_gateway = true
17 single_nat_gateway = true
18
19 tags = {
20 Project = "deftunes"
21 Environment = var.environment
22 }
23}1# Glue ETL Jobs
2resource "aws_glue_job" "extract_api_sessions" {
3 name = "deftunes-extract-api-sessions"
4 role_arn = aws_iam_role.glue_service_role.arn
5 glue_version = "3.0"
6 worker_type = "G.1X"
7 number_of_workers = 2
8 timeout = 60
9
10 command {
11 script_location = "s3://data-lake-bucket/scripts/glue/extract_api_sessions.py"
12 python_version = "3"
13 }
14
15 default_arguments = {
16 "--job-language" = "python"
17 "--TempDir" = "s3://data-lake-bucket/temp/"
18 "--enable-metrics" = "true"
19 "--enable-continuous-cloudwatch-log" = "true"
20 "--enable-spark-ui" = "true"
21 "--spark-event-logs-path" = "s3://data-lake-bucket/spark-logs/"
22 }
23}Orchestration
Airflow DAG Definitions
Apache Airflow is used to orchestrate the entire data pipeline with Directed Acyclic Graphs (DAGs).
1import os
2from datetime import datetime, timedelta
3
4from airflow import DAG
5from airflow.operators.dummy import DummyOperator
6from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
7from airflow.providers.amazon.aws.operators.glue_databrew import GlueDataBrewStartJobRunOperator
8from airflow.operators.python import PythonOperator
9from airflow.providers.docker.operators.docker import DockerOperator
10
11# Set default arguments for the DAG
12default_args = {
13 'owner': 'airflow',
14 'depends_on_past': False,
15 'email_on_failure': True,
16 'email_on_retry': False,
17 'email': ['data-pipeline-alerts@deftunes.com'],
18 'retries': 1,
19 'retry_delay': timedelta(minutes=5),
20}
21
22@dag(
23 default_args=default_args,
24 description="DefTunes pipeline for API data. Run AWS Glue jobs with parameters and perform data quality checks",
25 schedule_interval="0 0 1 * *", # Runs at midnight on the first day of every month
26 start_date=datetime(2023, 1, 1),
27 catchup=True,
28 max_active_runs=1,
29 tags=['deftunes', 'api'],
30 dag_id="deftunes_api_pipeline_dag",
31)
32def deftunes_api_pipeline():
33 # Start the pipeline
34 start = DummyOperator(task_id="start")
35
36 # Extract API sessions data
37 api_sessions_extract = GlueJobOperator(
38 task_id='extract_api_sessions',
39 job_name='deftunes-extract-api-sessions',
40 script_location='s3://deftunes-data-lake-{{ var.value.environment }}/scripts/glue/extract_api_sessions.py',
41 s3_bucket='deftunes-data-lake-{{ var.value.environment }}',
42 iam_role_name='deftunes-glue-service-role',
43 region_name='us-west-2',
44 script_args={
45 '--year': '{{ execution_date.strftime("%Y") }}',
46 '--month': '{{ execution_date.strftime("%m") }}',
47 '--source_table': 'api_sessions',
48 '--target_path': 's3://deftunes-data-lake-{{ var.value.environment }}/raw/api_sessions'
49 },
50 )
51
52 # Extract API users data
53 api_users_extract = GlueJobOperator(
54 task_id='extract_api_users',
55 job_name='deftunes-extract-api-users',
56 script_location='s3://deftunes-data-lake-{{ var.value.environment }}/scripts/glue/extract_api_users.py',
57 s3_bucket='deftunes-data-lake-{{ var.value.environment }}',
58 iam_role_name='deftunes-glue-service-role',
59 region_name='us-west-2',
60 script_args={
61 '--year': '{{ execution_date.strftime("%Y") }}',
62 '--month': '{{ execution_date.strftime("%m") }}',
63 '--source_table': 'api_users',
64 '--target_path': 's3://deftunes-data-lake-{{ var.value.environment }}/raw/api_users'
65 },
66 )
67
68 # Transform API data
69 transform_api_data = GlueJobOperator(
70 task_id='transform_api_data',
71 job_name='deftunes-transform-api-data',
72 script_location='s3://deftunes-data-lake-{{ var.value.environment }}/scripts/glue/transform_api_data.py',
73 s3_bucket='deftunes-data-lake-{{ var.value.environment }}',
74 iam_role_name='deftunes-glue-service-role',
75 region_name='us-west-2',
76 script_args={
77 '--year': '{{ execution_date.strftime("%Y") }}',
78 '--month': '{{ execution_date.strftime("%m") }}',
79 '--sessions_source_path': 's3://deftunes-data-lake-{{ var.value.environment }}/raw/api_sessions',
80 '--users_source_path': 's3://deftunes-data-lake-{{ var.value.environment }}/raw/api_users',
81 '--target_path': 's3://deftunes-data-lake-{{ var.value.environment }}/silver/api_data'
82 },
83 )
84
85 # Data quality check for sessions
86 dq_check_sessions = GlueDataBrewStartJobRunOperator(
87 task_id='data_quality_sessions',
88 job_name='deftunes-dq-sessions',
89 log_group_name='/aws-glue/databrew',
90 aws_conn_id='aws_default',
91 )
92
93 # Data quality check for users
94 dq_check_users = GlueDataBrewStartJobRunOperator(
95 task_id='data_quality_users',
96 job_name='deftunes-dq-users',
97 log_group_name='/aws-glue/databrew',
98 aws_conn_id='aws_default',
99 )
100
101 # Run dbt for data modeling
102 dbt_models = DockerOperator(
103 task_id='run_dbt_models',
104 image='deftunes/dbt:latest',
105 api_version='auto',
106 auto_remove=True,
107 command=f'run --profiles-dir /dbt --project-dir /dbt --target {{ var.value.environment }} --vars \'{{{{ "target_schema": "gold", "year": "{{ execution_date.strftime(\"%Y\") }}", "month": "{{ execution_date.strftime(\"%m\") }}" }}}}\' --select tag:api',
108 docker_url='unix://var/run/docker.sock',
109 volumes=['/opt/airflow/dbt:/dbt'],
110 environment={
111 'DBT_REDSHIFT_USER': '{{ var.value.redshift_user }}',
112 'DBT_REDSHIFT_PASSWORD': '{{ var.value.redshift_password }}',
113 'DBT_REDSHIFT_HOST': '{{ var.value.redshift_host }}',
114 'DBT_REDSHIFT_DATABASE': 'deftunes',
115 'DBT_SCHEMA': 'gold',
116 'AWS_ACCESS_KEY_ID': '{{ var.value.aws_access_key_id }}',
117 'AWS_SECRET_ACCESS_KEY': '{{ var.value.aws_secret_access_key }}',
118 'AWS_REGION': 'us-west-2'
119 },
120 )
121
122 # Create analytics views in Redshift
123 create_analytics_views = DockerOperator(
124 task_id='create_analytics_views',
125 image='deftunes/python:latest',
126 api_version='auto',
127 auto_remove=True,
128 command='python /scripts/create_analytics_views.py',
129 docker_url='unix://var/run/docker.sock',
130 volumes=['/opt/airflow/scripts:/scripts'],
131 environment={
132 'REDSHIFT_USER': '{{ var.value.redshift_user }}',
133 'REDSHIFT_PASSWORD': '{{ var.value.redshift_password }}',
134 'REDSHIFT_HOST': '{{ var.value.redshift_host }}',
135 'REDSHIFT_DATABASE': 'deftunes',
136 'REDSHIFT_PORT': '5439'
137 },
138 )
139
140 # End the pipeline
141 end = DummyOperator(task_id="end")
142
143 # Set task dependencies
144 start >> [api_sessions_extract, api_users_extract]
145 [api_sessions_extract, api_users_extract] >> transform_api_data
146 transform_api_data >> [dq_check_sessions, dq_check_users]
147 [dq_check_sessions, dq_check_users] >> dbt_models
148 dbt_models >> create_analytics_views
149 create_analytics_views >> end
150
151# Create the DAG
152deftunes_api_dag = deftunes_api_pipeline()1import os
2from datetime import datetime, timedelta
3
4from airflow import DAG
5from airflow.operators.dummy import DummyOperator
6from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
7from airflow.providers.amazon.aws.operators.glue_databrew import GlueDataBrewStartJobRunOperator
8from airflow.operators.python import PythonOperator
9from airflow.providers.docker.operators.docker import DockerOperator
10
11# Set default arguments for the DAG
12default_args = {
13 'owner': 'airflow',
14 'depends_on_past': False,
15 'email_on_failure': True,
16 'email_on_retry': False,
17 'email': ['data-pipeline-alerts@deftunes.com'],
18 'retries': 1,
19 'retry_delay': timedelta(minutes=5),
20}
21
22@dag(
23 default_args=default_args,
24 description="DefTunes pipeline for Songs data. Extract from database and process through the pipeline",
25 schedule_interval="0 0 1 * *", # Runs at midnight on the first day of every month
26 start_date=datetime(2023, 1, 1),
27 catchup=True,
28 max_active_runs=1,
29 tags=['deftunes', 'songs'],
30 dag_id="deftunes_songs_pipeline_dag",
31)
32def deftunes_songs_pipeline():
33 # Start the pipeline
34 start = DummyOperator(task_id="start")
35
36 # Extract songs data from database
37 songs_extract = GlueJobOperator(
38 task_id='extract_songs_data',
39 job_name='deftunes-extract-songs',
40 script_location='s3://deftunes-data-lake-{{ var.value.environment }}/scripts/glue/extract_songs.py',
41 s3_bucket='deftunes-data-lake-{{ var.value.environment }}',
42 iam_role_name='deftunes-glue-service-role',
43 region_name='us-west-2',
44 script_args={
45 '--year': '{{ execution_date.strftime("%Y") }}',
46 '--month': '{{ execution_date.strftime("%m") }}',
47 '--database_name': 'deftunes',
48 '--table_name': 'songs',
49 '--connection_name': 'deftunes-db-connection',
50 '--s3_target_path': 's3://deftunes-data-lake-{{ var.value.environment }}/raw/songs'
51 },
52 )
53
54 # Extract artists data from database
55 artists_extract = GlueJobOperator(
56 task_id='extract_artists_data',
57 job_name='deftunes-extract-artists',
58 script_location='s3://deftunes-data-lake-{{ var.value.environment }}/scripts/glue/extract_artists.py',
59 s3_bucket='deftunes-data-lake-{{ var.value.environment }}',
60 iam_role_name='deftunes-glue-service-role',
61 region_name='us-west-2',
62 script_args={
63 '--year': '{{ execution_date.strftime("%Y") }}',
64 '--month': '{{ execution_date.strftime("%m") }}',
65 '--database_name': 'deftunes',
66 '--table_name': 'artists',
67 '--connection_name': 'deftunes-db-connection',
68 '--s3_target_path': 's3://deftunes-data-lake-{{ var.value.environment }}/raw/artists'
69 },
70 )
71
72 # Transform songs data
73 transform_songs = GlueJobOperator(
74 task_id='transform_songs_data',
75 job_name='deftunes-transform-songs',
76 script_location='s3://deftunes-data-lake-{{ var.value.environment }}/scripts/glue/transform_songs.py',
77 s3_bucket='deftunes-data-lake-{{ var.value.environment }}',
78 iam_role_name='deftunes-glue-service-role',
79 region_name='us-west-2',
80 script_args={
81 '--year': '{{ execution_date.strftime("%Y") }}',
82 '--month': '{{ execution_date.strftime("%m") }}',
83 '--source_path': 's3://deftunes-data-lake-{{ var.value.environment }}/raw/songs',
84 '--target_path': 's3://deftunes-data-lake-{{ var.value.environment }}/silver/songs'
85 },
86 )
87
88 # Transform artists data
89 transform_artists = GlueJobOperator(
90 task_id='transform_artists_data',
91 job_name='deftunes-transform-artists',
92 script_location='s3://deftunes-data-lake-{{ var.value.environment }}/scripts/glue/transform_artists.py',
93 s3_bucket='deftunes-data-lake-{{ var.value.environment }}',
94 iam_role_name='deftunes-glue-service-role',
95 region_name='us-west-2',
96 script_args={
97 '--year': '{{ execution_date.strftime("%Y") }}',
98 '--month': '{{ execution_date.strftime("%m") }}',
99 '--source_path': 's3://deftunes-data-lake-{{ var.value.environment }}/raw/artists',
100 '--target_path': 's3://deftunes-data-lake-{{ var.value.environment }}/silver/artists'
101 },
102 )
103
104 # Enrich songs with artist data
105 enrich_songs = GlueJobOperator(
106 task_id='enrich_songs_data',
107 job_name='deftunes-enrich-songs',
108 script_location='s3://deftunes-data-lake-{{ var.value.environment }}/scripts/glue/enrich_songs.py',
109 s3_bucket='deftunes-data-lake-{{ var.value.environment }}',
110 iam_role_name='deftunes-glue-service-role',
111 region_name='us-west-2',
112 script_args={
113 '--year': '{{ execution_date.strftime("%Y") }}',
114 '--month': '{{ execution_date.strftime("%m") }}',
115 '--songs_path': 's3://deftunes-data-lake-{{ var.value.environment }}/silver/songs',
116 '--artists_path': 's3://deftunes-data-lake-{{ var.value.environment }}/silver/artists',
117 '--target_path': 's3://deftunes-data-lake-{{ var.value.environment }}/silver/enriched_songs'
118 },
119 )
120
121 # Data quality check
122 dq_check = GlueDataBrewStartJobRunOperator(
123 task_id='data_quality_songs',
124 job_name='deftunes-dq-songs',
125 log_group_name='/aws-glue/databrew',
126 aws_conn_id='aws_default',
127 )
128
129 # Run dbt for data modeling
130 dbt_models = DockerOperator(
131 task_id='run_dbt_models',
132 image='deftunes/dbt:latest',
133 api_version='auto',
134 auto_remove=True,
135 command=f'run --profiles-dir /dbt --project-dir /dbt --target {{ var.value.environment }} --vars \'{{{{ "target_schema": "gold", "year": "{{ execution_date.strftime(\"%Y\") }}", "month": "{{ execution_date.strftime(\"%m\") }}" }}}}\' --select tag:songs',
136 docker_url='unix://var/run/docker.sock',
137 volumes=['/opt/airflow/dbt:/dbt'],
138 environment={
139 'DBT_REDSHIFT_USER': '{{ var.value.redshift_user }}',
140 'DBT_REDSHIFT_PASSWORD': '{{ var.value.redshift_password }}',
141 'DBT_REDSHIFT_HOST': '{{ var.value.redshift_host }}',
142 'DBT_REDSHIFT_DATABASE': 'deftunes',
143 'DBT_SCHEMA': 'gold',
144 'AWS_ACCESS_KEY_ID': '{{ var.value.aws_access_key_id }}',
145 'AWS_SECRET_ACCESS_KEY': '{{ var.value.aws_secret_access_key }}',
146 'AWS_REGION': 'us-west-2'
147 },
148 )
149
150 # Create analytics views
151 create_analytics_views = DockerOperator(
152 task_id='create_analytics_views',
153 image='deftunes/python:latest',
154 api_version='auto',
155 auto_remove=True,
156 command='python /scripts/create_analytics_views.py',
157 docker_url='unix://var/run/docker.sock',
158 volumes=['/opt/airflow/scripts:/scripts'],
159 environment={
160 'REDSHIFT_USER': '{{ var.value.redshift_user }}',
161 'REDSHIFT_PASSWORD': '{{ var.value.redshift_password }}',
162 'REDSHIFT_HOST': '{{ var.value.redshift_host }}',
163 'REDSHIFT_DATABASE': 'deftunes',
164 'REDSHIFT_PORT': '5439'
165 },
166 )
167
168 # End the pipeline
169 end = DummyOperator(task_id="end")
170
171 # Set task dependencies
172 start >> [songs_extract, artists_extract]
173 songs_extract >> transform_songs
174 artists_extract >> transform_artists
175 [transform_songs, transform_artists] >> enrich_songs
176 enrich_songs >> dq_check
177 dq_check >> dbt_models
178 dbt_models >> create_analytics_views
179 create_analytics_views >> end
180
181# Create the DAG
182deftunes_songs_dag = deftunes_songs_pipeline()Documentation
Project Setup Guide
Follow these steps to set up the DeFtunes data pipeline in your environment.
Prerequisites
- AWS Account with appropriate permissions
- Terraform v1.5+ installed
- Docker and Docker Compose installed
- Python 3.10+ installed
- AWS CLI configured with appropriate credentials
Installation Steps
Clone the repository
bash1git clone https://github.com/YKaanKaya/deftunes-data-pipeline.git 2cd deftunes-data-pipelineCreate infrastructure with Terraform
bash1cd terraform 2# Initialize Terraform 3terraform init 4 5# Create a terraform.tfvars file with your configuration 6cat > terraform.tfvars << EOL 7aws_region = "us-west-2" 8environment = "dev" 9redshift_username = "admin" 10redshift_password = "YourSecurePassword" 11redshift_node_type = "dc2.large" 12db_username = "admin" 13db_password = "YourSecureDBPassword" 14EOL 15 16# Apply the Terraform configuration 17terraform applySet up Airflow
bash1cd ../airflow 2 3# Build the Airflow Docker image 4docker build -t deftunes-airflow:latest . 5 6# Create an .env file with your AWS credentials 7cat > .env << EOL 8AWS_ACCESS_KEY_ID=your_access_key 9AWS_SECRET_ACCESS_KEY=your_secret_key 10AWS_REGION=us-west-2 11AIRFLOW_WWW_USER_USERNAME=admin 12AIRFLOW_WWW_USER_PASSWORD=admin 13EOL 14 15# Start Airflow services 16docker-compose up -dConfigure data sources
Edit the configuration files in the
configdirectory to point to your data sources:bash1cd ../config 2# Edit the source configuration file 3nano sources.yamlTest the pipeline
bash1# Trigger a test run of the workflow 2cd ../scripts 3./trigger_workflow.sh deftunes-api-data-workflow-dev
